Data Generation Concepts
Now that you have mastered the first tutorials and have had a glance on Benerator's features, it is time for an in-depth introduction to data generation:
Naming
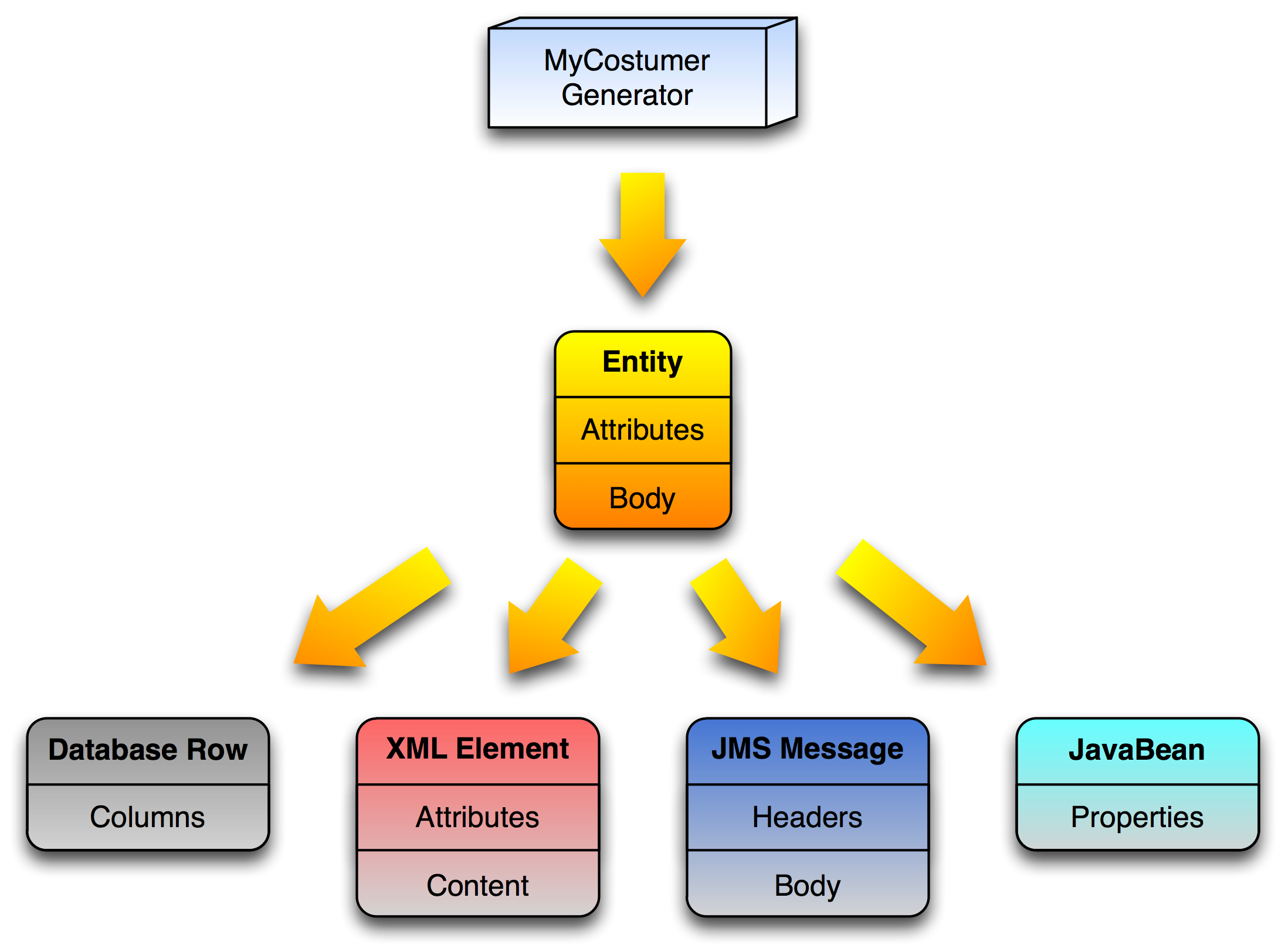
Business objects are called entity in this book, their contained simple type data are attributes.
Entity Data
Benerator generates entities in a platform-independent manner (internally using the class com.rapiddweller.model.data.Entity. An entity will be
interpreted individually depending on the target system. It can be mapped to
-
relational data (DB)
-
hierarchical data (XML)
-
graphs (JavaBeans)
-
attributed payload holders (File, JMS Message, HTTP invocations)
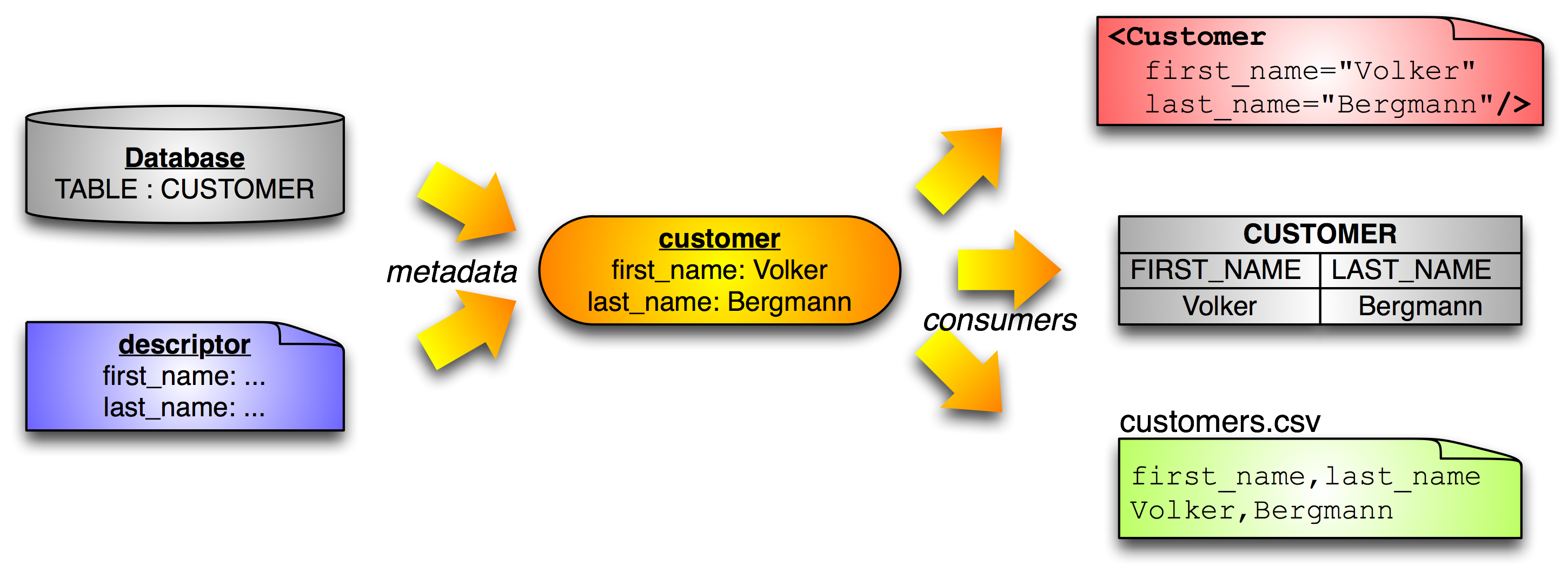
So you can use an abstract, generic way of defining and generating business objects and reuse it among colleagues, companies and target platforms. An address generator defined once can be used for populating customer tables in a database or creating XML order import batch files.
Metadata is platform-neutral too. So Benerator can import metadata definitions from a database and use it for generating XML data:
Entities can have
-
an arbitrary number of simple-type attributes (like database tables or XML attributes). They can have a cardinality >` 1, too (like arrays of simple types)
-
sub components of entity type (like XML sub elements)
-
a body of simple type (like XML simpleType elements, files or JMS messages)
Simple Data Types
Benerator abstracts simple types too. These are the predefined simple types:
| Benerator type | JDBC type name | JDBC type code | Java type |
|---|---|---|---|
| byte | Types.BIT | -7 | java.lang.Byte |
| byte | Types.TINYINT | -6 | java.lang.Byte |
| short | Types.SMALLINT | 5 | java.lang.Short |
| int | Types.INTEGER | -5 | java.lang.Integer |
| big_integer | Types.BIGINT | -5 | java.lang.Long |
| float | Types.FLOAT | 6 | java.lang.Float |
| double | Types.DOUBLE | 8 | java.lang.Double |
| double | Types.NUMERIC | 2 | java.lang.Double |
| double | Types.REAL | 7 | java.lang.Double |
| big_decimal | Types.DECIMAL | 3 | java.math.BigDecimal |
| boolean | Types.BOOLEAN | 16 | java.lang.Boolean |
| char | Types.CHAR | 1 | java.lang.Character |
| date | Types.DATE | 91 | java.lang.Date |
| date | Types.TIME | 92 | java.lang.Date |
| timestamp | Types.TIMESTAMP | 93 | java.lang.Timestamp |
| string | Types.VARCHAR | 12 | java.lang.String |
| string | Types.LONGVARCHAR | -1 | java.lang.String |
| string | Types.CLOB | 2005 | java.lang.String |
| object | Types.JAVA_OBJECT | 2000 | java.lang.Object |
| binary | Types.BINARY | -2 | byte[] |
| binary | Types.VARBINARY | -3 | byte[] |
| binary | Types.VARBINARY | -4 | byte[] |
| binary | Types.BLOB | 2004 | byte[] |
| (heuristic) | Types.OTHER | 1111 | (heuristic) |
Oracle's NCHAR, NVARCHAR2 and NCLOB types are treated like strings.
The following JDBC types are not supported: DATALINK (70), NULL (0), DISTINCT (2001), STRUCT (2002), ARRAY (2003), REF ( 2006). If you need them, create an issue or get in touch.
Data Characteristics
Distribution Concept
There are two special issues which often remain unaddressed in testing:
-
using realistic probability distributions (e.g. popularity of shop items)
-
creating unique values (e.g. IDs or unique phone numbers for fraud checking)
For these purposes, rapiddweller Benerator provides several interfaces, which extend a common interface, Distribution. The most important ones are
-
WeightFunction
-
Sequence
For a list of predefined distributions, see Section 8.2, “Distributions”.
Generation Stages
The result of data generation typically consists of
-
a small predefined and well-known core data set
-
large data volumes that are generated randomly and extends the core data

This approach has the advantage of supporting different test types with the same generation setup: It is essential for performance tests to have a unit- and integration-tested system and you can strongly simplify the testing procedure by reusing data definitions from unit- and integration tests as core data for a mass data generation.
Regarding the technical steps involved, a generation process employs up to six stages for each system involved:

-
System Initialization, e.g. by start scripts and DDL scripts
-
Precondition Checking for verifying that data required for data generation is available
-
Core Data Generation for creating a predefined data set
-
Mass Data Generation for scaling data amounts of large volume
-
Data Postprocessing for performing complex operations
-
Result Validation for verifying the generated data
System Initialization Stage
In the system initialization stage you typically use scripts for starting and initializing the systems involved, e.g.
-
start database by shell script
-
run SQL script
-
start application server
For starting a database with a shell script and initializing it with a SQL script, you could write:
<setup>
<execute type="shell">`sh ./startdb.sh &`</execute>
<execute target="db" type="sql" onError="warn">
DROP TABLE db_user;
CREATE TABLE db_user (id int NOT NULL,
name varchar(30) NOT NULL,
PRIMARY KEY (id),
);
</execute>
</setup>
As you see, scripts can be inlined or imported from files. See 'Scripting' for a full introduction.
Precondition Checking Stage
Complex data generation is often split up int several stages of which each has its own preconditions. For example, if you want to generate orders for all kinds of products, you may want to assure that at least one product of each category is defined in the system.
The simplest way to perform precondition checks is the <evaluate> element, e.g. checking for categories without product:
<evaluate assert="{js:result == 0}" target="db"> select count(*) from db_category left join db_product on db_product.category_id = db_category.id
where db_product.category_id is null</evaluate>
The <evaluate> element works as follows: First it evaluates a script the same way like a <execute> element does – In this example, the 'select'
query is performed on the database. Then the result into a variable named 'result' and the '
assert' condition is evaluated which checks the value of the result and returns true or false. if the assertion resolves to 'false', Benerator raises
an error.
In this example, an error is raised if there is a category without any product assigned.
You can use an arbitrary expression language for performing the check. Like in <execute>, a prefix with colon can be used to indicate the script
language. You can optionally add an 'id' attribute which will make Benerator put the evaluation result into the context with this id.
You can also call DB Sanity for verifying the preconditions, see 'DB Sanity'.
Core Data Generation Stage
For predefined data generation it is most convenient to import core data from a file - this gives you full control and easy configuration by an editor and is the most reliable source for reproducible data. Currently, the most convenient file formats for this task are DbUnit XML files (one file with several tables) and CSV (one file per table).
<setup>
<!-- import integration test data for all tables from one DbUnit file -->
<iterate source="core.dbunit.xml" consumer="db" />
<!-- import predefined products from a CSV file -->
<iterate type="db_product" source="demo/shop/products.import.csv" encoding="utf-8" consumer="db" />
</setup>
Fixed column width files and SQL files can be used too. If you need to import data of other formats you can easily write a parser and use it directly from Benerator (See 'Custom EntitySources').
Mass Data Generation Stage
Mass data generation is the primary goal of Benerator. It is mainly performed by <generate> descriptors, which
describe the creation of synthetic data, but may also include the import and reuse of information from external sources by an <iterate> descriptor.
See 'Descriptor File Format' and 'Advanced Topics' for a description.
Data Postprocessing Stage
If your system has complex business logic (typically workflows), you will encounter generation requirements that are easier to satisfy by calling application business logic than by a pure descriptor-based generation.
For example, you might need to generate performance test data for a mortgage application: People may apply for a mortgage, enter information about their house, incomes and expenses, their application is rated by some rule set, and the mortgages finally is granted or rejected. Then you have complex logic (rating) that is not necessarily useful to be reproduced for data generation. It is easiest to call the business logic directly.
This can be done in two ways:
-
Scripts : Having script commands inlined in the Benerator descriptor file or called from external files, e.g. rapiddwellerScript, JavaScript, Groovy, Ruby, Python. See 'Scripting'
-
Tasks : Programming own Java modules that are invoked by Benerator. See 'Tasks'
Result Validation Stage
Data generation may become quite tricky. For improving maintainability it is recommended to perform validations after data generation:
-
Checking the number of generated objects
-
Checking invariants
-
Checking prerequisites for specific performance tests
You can do so with the <evaluate/> element, e.g. checking the number of generated customers
<evaluate assert="{js:result = 5000000}" target="db">select count(*) from db_user</evaluate>
The <evaluate> element was described above in the 'Precondition Checking' section.
You can also use DB Sanity for verifying the preconditions; see 'DB Sanity'.
Metadata Concepts
Benerator processes metadata descriptors that can be imported from systems like databases and can be overwritten manually. Benerator automatically generates data that matches the (e.g. database) constraints. So, when it encounters a table defined like this:
CREATE TABLE db_user (
...
active SMALLINT DEFAULT 1 NOT NULL,
...
);
When generating data for the user table, Benerator will automatically generate all users with active set to 1:
<generate type="db_user" count="100" consumer="db"/>
If you specify active as an attribute, you inherit a new setting from the parent descriptor, dropping the parent's configuration of values=1 and adding a new one, e.g. the configuration
<generate type="db_user" count="100" consumer="db">
<attribute name="active" values="0,1"/>
</generate>
will cause generation of 50% 0 and 50% 1 values.
Case Sensitivity
Benerator has a heuristic case-sensitivity: It needs to combine metadata from different types of systems of which some may be case-sensitive, some may not. So Benerator first assumes case-sensitivity when looking for a type. If the type is found in the same capitalization, this information used. If it is not found, Benerator falls back to searching the type in a case-insensitive manner.
Namespaces
Benerator has a heuristic namespace support, similar to case-sensitivity handling: when looking up a descriptor by name, Benerator first searches the name in its assigned namespace. If the type is found there, this information used. If it is not found, Benerator falls back to searching the type in all available namespaces.
<setting> and Benerator identifiers
A Benerator identifier (variable, entity or bean name) may contain only ASCII letters, numbers and underscores (no dot !) and is defined using
a <setting> element - either in the descriptor file, e.g.
<setting name="user_count" value="1000000"/>
or in a properties file, e.g. myproject.properties:
user_count="1000000
which is then included in the descriptor file:
<include uri="myproject.properties"/>
Of course you can evaluate variables for defining other variables as well by using a script expression:
<setting name="event_count" value="{user_count * 10}"/>
A property can also refer to another element of the generation context:
<setting name="limit" ref="maxCount"/>
And it can be set calling a generator object:
<setting name="fileNumber" source="new DBSequenceGenerator('my_seq', db)"/>
You can define default values for properties. If no property value has been defined before, the property is set to this value:
<setting name="stage" default="development" />
Benerator Components

Entities as well as their attributes can be imported from storage systems , data files or specific generators . They then serve as prototypes of which attributes may be overwritten by another generator ( overriding generator ), e.g. for anonymization.
Alternatively, entities may be generated completely synthetically .
Entities and each entity attribute can be converted by a specific Converter object.
Validators assure validity of the generated entities and attributes. All entities that fail validation are discarded.
Finally, generated data is consumed by storing it in a storage system (e.g. database), writing it to a data file or using it in a custom Consumer implementation.
Instantiating Global Components
You ca define global components in a Spring-like syntax:
<bean id="helper" class="com.my.Helper">
<property name="min" value="5"/>
<property name="max" value="23"/>
</bean>
For details on this syntax and other variants, see the section “JavaBeans and the Benerator Context”. You can refer to such an object by its id (' helper' in this case).
Instantiating Local Components
The following chapters will introduce you to the usage of each component type available in Benerator. They have common styles of definition and
referral. If a component needs to be reused in different places, you would create it with a <bean> element and apply referral to use it. If you do
not need to reuse one component in different places, there are more concise inline instantiation styles available:
-
default construction
-
parameterized construction
-
property-based construction
Referral
Any class can be instantiated and made available to Benerator by using a bean element, e.g. the 'helper' instance above, you can use it like this:
<attribute name="number" generator="helper"/>
This is called referral.
Default Construction
If you specify just a class name, Benerator will create an instance of the class by invoking the default constructor. Be aware that the class needs a public no-argument constructor for being instantiated this way:
<attribute name="number" generator="com.my.Helper"/>
Parameterized Construction
You can as well specify the 'new' keyword, a class name and constructor parameters. Benerator will then search a constructor with matching parameters and invoke it. If the class has several constructors with the same number of parameters Benerator might choose the wrong one, so it is good practice to have just one constructor for each possible number of parameters.
<attribute name="number" generator="new com.my.Helper(5, 23)"/>
Property-based Construction
This is the most elegant and maintainable inline construction style, you specify the 'new' keyword, the class name and, in square brackets, a comma-separated list of name-value pairs for each JavaBean property. Benerator uses a default constructor and the corresponding set...() methods to initialize the object.
<attribute name="number" generator="new com.my.Helper{min=5, max=23}"/>
Descriptive Data Generation
Descriptive Data Generation means defining elementary data restrictions , e.g. nullability and string lengths. For example, an attribute may have only one of an enumeration of values. They can be defined as a comma-separated list:
<attribute name="issuer" values="'AMEX','VISA'" />
For a list of descriptive attribute metadata, see Section 3.38, “Attribute Metadata Reference” Descriptive metadata can be imported automatically from database schema metadata and be used for automatic database-valid data generation:
Default Data Generation
Based on descriptive metadata, Benerator applies several defaults for generating database-valid data.
All nullable attributes are generated as null by default.
Primary keys are generated as integral numbers by default, starting from 1 and increased by 1 consecutively. Primary keys of string type are handled similarly.
Foreign keys are resolved automatically. For avoiding illegal generation cases, Benerator assumes any foreign key relation to be one-to-one by default. Many-to-one relationships need to be configured manually.
Now have a look at an example for generating credit cards in a database:

Benerator reads the metadata for the table credit_card from a database. This results in descriptive metadata , saying that a credit_card entity has three attributes: issuer and number of type string and validUntil of type date. All of them may not be null and the issuer attribute has a maximum length of 20 characters, the number of 16 characters.
This is enough information to make Benerator generate, e.g. 50000 credit cards with a trivial setup:
<generate type="credit_card" count="500000" consumer="db"/>
The resulting entries are database-valid automatically.
Constructive Data Generation
Constructive metadata describes methods of data generation, e.g. import from a data source or stochastic number generation.
We can improve the credit card example from above by adding own, constructive metadata to the descriptive ones imported from the database:

This way we can already satisfy simple validation algorithms, but not yet sophisticated ones that performs a checksum validation.
For a complete reference of metadata configuration, see Section 3.38, “Attribute Metadata Reference”, Section 3.25, “Generating IDs” and Section 3.26, “Resolving Relations”
Validating Data Generation
Suppose you have a validation component available, but do not know all details necessary for constructing valid data. In such a case, you can set up a constructive data generation and combine it with the validation module. So take the setup from the chapter before, write an adapter to your validation component and include it in Benerator's data generation:

Your setup will then create random credit card setups and the credit card validator will discard the invalid ones. For the definition of custom validators, see Section 9.7, “Custom Validators”.
Prototype-based Data Generation
The examples above are satisfactory for almost all cases, but if you need to satisfy very difficult validity conditions you need ultimate control over generation. For our credit card example, you might have a validator module that connects to the credit card company and validates if the account really exists

You can generate prototypes with custom generators or import them as samples (See Section 3.11, “Sample-based Data Generation”).
Sample-based Data Generation
The examples above are satisfactory for almost all cases, but there are cases in which you need to use a predefined set of entities. For our credit card example, the tested application might check credit cards by connecting to the credit card company and query if the account really exists. In such a case you typically define a file with known credit card numbers to use:

<iterate type="credit_card" source="credit_cards.csv" consumer="db" />
You can use different types of data sources for templates:
-
Files : CSV, fixed column width files, DbUnit. For importing data of custom file formats or from other sources, see Section 9.9, “Custom EntitySources”
-
Storage Systems: Relational databases For importing data of proprietary storage systems, see Section 9.12, “Custom StorageSystems”
Variables
When importing entities from a data source you will need to map data in some way. This is where the variable concept comes in: You can define
a <variable> as an auxiliary generator inside a <generate> descriptor and assign it a name (e.g. 'person'). In each entity generation this
generator will provide a new generated object under the assigned name ('person'). So, if you want to access a part of a composite generated object you
can query it e.g. by a script expression like person.familyName:
<generate type="customer" consumer="ConsoleExporter">
<variable name="person" generator="PersonGenerator" />
<attribute name="lastName" script="person.familyName" />
</generate>
For defining a variable, you can use the same syntax elements like for an attribute. But the type of data that the variable can generate is much less restricted. A variable may
-
use an EntitySource or Generator that creates entity objects.
-
use a Generator that creates Maps or JavaBean objects. Their map values or bean properties can be queried from a script the same way as for an entity
-
execute a SQL query (e.g. name="c_customer" source="db" selector="select id, name from customer where rating = 0") of which column values may be accessed by a script (e.g. script="{c_customer[0]}" for the id).
Combining components and variables
Starting with Benerator 0.7, sub elements of a <generate> loop are evaluated in the order in which they appear in the descriptor file, in earlier
versions they were reordered before processing. When nesting <generate> loops be aware, that each instance of the outer loop is consumed before a
sub-generate is called, so it does not make sense to define an <attribute>, <id> or <reference> after the sub-generate statement.
Referring Files
In most cases, Files are referred by URIs. A URI may be
-
a simple local (data.csv) or
-
an absolute filename (C:\datagen\data.csv) or a
-
a URL (http://my.com/datagen/data.csv).
For FTP access, use RFC1738 for encoding user name, password and file format, e.g. ftp://user: password@server/dir/file;type=i
Protocols
Currently Benerator supports only file URIs for reading and writing and HTTP and FTP URIs for reading. Support of further protocols is possible and planned for future releases.
Relative URIs
Relative URIs are resolved in a HTML hypertext manner: A relative URL is interpreted relative to a 'base URI' which is the path of the Benerator descriptor file. If file lookup fails, Benerator searches the file relative to the current directory. If that fails to, Benerator tries to retrieve the file from the Java classpath.
Benerator recognizes absolute paths under Windows (e.g. C:\test) and Unix (/test or ~/test). When in doubt, mark the URL as file URL: file:///C:/test or file:///test.
Importing Entities
Entities can be imported from 'system's, files or other generators. A typical application is to (re)use a DBUnit setup file from your (hopefully existing ;-) unit tests:
<iterate source="shop/shop.dbunit.xml" consumer="db"/>
For importing DbUnit files, follow the naming conventions using the suffix .dbunit.xml.
Each created entity is forwarded to one or more consumers, which usually will persist objects in a file or system, but might also be used to post-process created entities. The specified object needs to implement the Consumer or the system interface. When specifying a system here, it will be used to store the entities. File exporters (for CSV and fixed column width files) implement the Consumer interface.
Custom Importers
New import formats can be supported by implementing the EntitySource interface with a JavaBean implementation, instantiating it as bean and referring it by its id with a 'source' attribute, e.g.
<setup>
<bean id="products_file" class="com.rapiddweller.platform.fixedwidth.FixedWidthEntitySource">
<property name="uri" value="shop/products.import.fcw"/>
<property name="entity" value="product"/>
<property name="properties" value="ean_code[13],name[30],price[8r0]"/>
</bean>
<iterate type="product" source="products_file" consumer="ConsoleExporter"/>
</setup>
Consumers
Consumers are the objects that finally receive the data after creation, conversion and validation. Consumers can be files, storage systems or custom JavaBeans that implement the Consumer interface. They are not supposed to mutate generated data. That is reserved to Converters.
Specifying Consumers
A <generate> element may have consumers in <consumer> sub-elements or in a comma-separated list in a consumer attribute, e.g. consumer="a,b". A
consumer sub element has the same syntax as a <bean> element, e.g.
<generate type="db_product">
<consumer class="com.my.SpecialConsumer">
<property name="format" value="uppercase"/>
</consumer>
</generate>
A consumer attribute may hold a comma-separated list consisting of
-
names of previously defined beans
-
fully qualified class names of consumer implementations
Examples:
<database id="db" .../>
The <database> declaration will be described later.
<setup>
<bean id="special" class="com.my.SpecialConsumer">
<property name="format" value="uppercase"/>
</bean>
<generate type="db_product" consumer="db,special"/>
</setup>
or
<setup>
<bean id="special" class="com.my.SpecialConsumer">
<property name="format" value="uppercase"/>
</bean>
<generate type="db_product" consumer="com.my.SpecialConsumer"/>
</setup>
Consumer Life Cycle
In most cases Consumers relate to heavyweight system resources, so it is important to know their life cycle. There are two different types of life cycle:
-
Global Consumer: A consumer defined as a
<bean>has a global scope (thus is called 'global consumer') and is closed when Benerator finishes. So you can use the same consumer instance for consuming output of several different<generate>and<iterate>blocks. -
Local Consumer: A consumer defined 'on the fly' in a generate/iterate block (by 'new', class name or
<consumer>) has a local scope and is immediately closed when its generate/iterate block finishes. If you want to generate a file and iterate through it afterwards you need to have it closed before. The most simple way to assure this is to use a local consumer in file generation.
Exporting Data to Files
You will need to reuse some of the generated data for setting up (load) test clients. You can export data by simply defining an appropriate consumer:
<setup>
<import platforms="fixedwidth" />
<generate type="db_product" consumer="db">
<consumer class="FixedWidthEntityExporter">
<property name="uri" value="products.fcw"/>
<property name="properties" value="ean_code[13],name[30l],price[10r0]"/>
</consumer>
</generate>
</setup>
Post Processing Imported or Variable Data
When importing data or using helper variables, you may need to overwrite imported attributes. You can do so by
-
overwriting them (e.g. with a generated ID value) or
-
manipulating the imported attribute value with a script (e.g. replacing CARD=Y/N with 0/1) or
-
using a map to convert between predefined values or
-
using a converter to transform attributes individually (e.g. for converting strings to uppercase)
You could also combine the approaches
overwriting post processing
<iterate type="TX" source="tx.ent.csv" >
<id name="ID" generator="IncrementalIdGenerator" />
</iterate>
"script" post processing
<iterate type="TX" source="tx.ent.csv">
<attribute name="CARD" script="TX.CARD == 'Y' ? 1 : 0" />
</iterate>
"map" post processing
For mapping imported (or generated) values, you can use a convenient literal syntax, listing mappings in a comma-separated list of assignments in the form original_value ->` mapped_value. Values need to be literals here too, so don't forget the quotes around strings and characters! This is a postprocessing step, so it can be combined with an arbitrary generation strategy.
Example
<iterate type="db_user" source="db">
<variable name="p" generator="person" />
<attribute name="gender" script="p.gender.name()" map="'MALE'->`'m','FEMALE'->`'f'" />
</iterate>
In a script, the keyword this refers to the entity currently being generated/iterated.
"converter" post processing
For more intelligent/dynamic conversions, you can inject a converter, e.g. for converting strings to upper case:
<iterate type="TX" source="tx.ent.csv">
<attribute name="PRODUCT" script="{this.PRODUCT}" converter="CaseConverter" />
</iterate>
Anonymizing Production Data
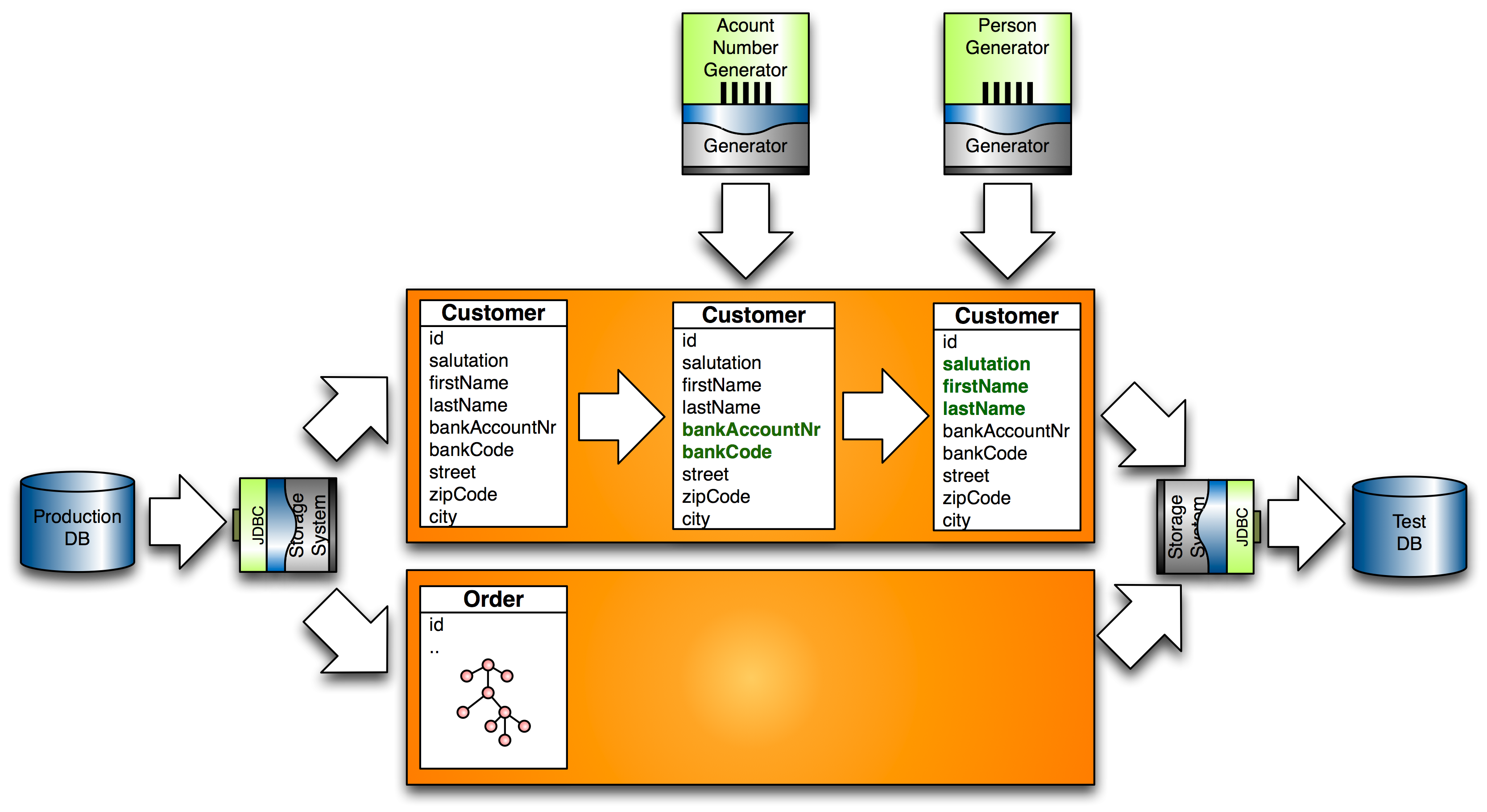
When importing data from production systems, you can anonymize it by overwriting its attributes as described in 'post processing import data'. If you need to assure multi-field-dependencies when overwriting, you can choose a prototype-base approach: import data from one source and merge it with prototypes that are generated or imported from another source.
In the following example, customers are imported from a database table in a production database (prod_db), anonymized and exported to a test database (test_db). All attributes that are not overwritten, will be exported as is. Since customer names and birth dates need to be anonymized, a prototype generator (...PersonGenerator) is used to generate prototypes (named person) whose attributes are used to overwrite production customer attributes:
<iterate source="prod_db" type="db_customer" consumer="test_db">
<variable name="person" generator="com.rapiddweller.domain.person.PersonGenerator"/>
<attribute name="salutation" script="person.salutation" />
<attribute name="first_name" script="person.givenName" />
<attribute name="last_name" script="person.familyName" />
<attribute name="birth_date" nullable="false" />
</iterate>
"condition"
When anoymizing or importing, data one sometimes meets difficult multi-field-constraints of the form „if field A is set then field B must be set and field C must be null“. It many cases, an easy solution is to import data, mutate only non-null fields and leave null-valued fields as they are. A short syntax element to do so is the condition attribute. It contains a condition and when added to a component generator, the generator is only applied if the condition resolves to true:
<iterate source="db1" type="customer" consumer="">
<attribute name="vat_no" condition="this.vat_no != null" pattern="DE[1-9][0-9]{8}" unique="true" />
</iterate>
Converters
Converters are useful for supporting using custom data types (e.g. a three-part phone number) and common conversions ( e.g. formatting a date a date as string). Converters can be applied to entities as well as attributes by specifying a converter attribute:
<generate type="TRANSACTION" consumer="db">
<id name="ID" type="long" strategy="increment" param="1000" />
<attribute name="PRODUCT" source="{TRANSACTION.PRODUCT}" converter="CaseConverter"/>
</generate>
For specifying Converters, you can
-
use the class name
-
refer a JavaBean in the Benerator context
-
provide a comma-separated Converter list in the two types above
Benerator supports two types of converters:
-
Classes that implement the interface com.rapiddweller.common.Converter
-
Classes that extend the class java.text.Format
If the class has a 'pattern' property, Benerator maps a descriptor's pattern attribute to the bean instance property.
Validators
Validators assist you in assuring validity of generated data. Validators can be applied to attributes and full entities. They intercept in data generation: If a generated item is invalid, it will be discarded and regenerated transparently. This is a cheap way of fulfilling complex constraints which are only partially known: If you have a class or system that can validate this data, you can set up a heuristic generation which has a high probability of succeeding and simply discard the invalid ones. If the ratio of invalid objects is more than 99%, Benerator will give you a warning since this is likely to impact generation performance. If the ratio rises to 99.9%, Benerator will terminate with an exception.
For specifying Validators, you can
-
use the class name
-
refer a JavaBean in the Benerator context
-
provide a comma-separated Validator list in the two types above
Creating random Entities
Entities can be generated without any input files - Benerator provides a rich set of Generator implementations. When using <generate> without a '
source' attribute, the registered systems (e.g. the database are requested for metadata). From the metadata, attributes are generated that match the
metadata (e.g. database) constraints, as column length, referenced entities and more. By default, associations are treated as one-to-one associations.
With Benerator's many useful defaults, you have a minimum effort on initial configuration:
<generate type="db_user" count="1000" consumer="db" />
Id generation defaults to an increment strategy and for all other columns useful defaults are chosen.
Entities are generated as long as each attribute generator is available and limited by the number specified in the ' count' attribute. The 'pageSize' defines the number of creations after which a flush() is applied to all consumers (for a database system this is mapped to a commit).
Entity Count
There are different ways of determining or limiting the number of generated entities:
-
the count attribute specifies a fix number of instances to create
-
the minCount, maxCount and countDistribution attributes let Benerator choose an instance count with the specified characteristics.
-
availability of the component generators
Data generation stops if either the limit count is reached or a component generator becomes unavailable.
If you have problems with unexpectedly low numbers of generated entities you can set the log category com.rapiddweller.benerator.STATE to debug level.
Using Predefined Entities
When iterating predefined entities (e.g. imported from file or database), Benerator's default behaviour is to serve each item exactly once and in the order as provided. You can change that behaviour in many ways, but need to be aware of the iterated data volume:
For small data sets (`< 100,000 items) you can apply a distribution method (see Section 3.29, “Applying a Weight Function” or Section 3.30, “Applying a Sequence”). This will cause Benerator to load all available instances into memory and serve them as specified by the distribution: A WeightFunction will tell Benerator how often to serve an instance of a certain list index, a Sequence will tell each index consecutively. Depending on the Sequence, data can be provided uniquely or weighted.
For big data sets (>` 100,000 items) you need to be more conservative, since the data volume is not supposed to fit into main memory. You have two options here: cyclic iteration and proxy iteration. Actually, both types can be combined.
Iterating Predefined Entities Consecutively
By default, imported entities are processed consecutively and only once.
When setting cyclic="true" Benerator serves the imported data consecutively too but does not stop when it reaches the end. Instead it restarts iteration. Beware: For SQL queries this means that the query is reissued, so it may have a different result set than the former invocation.
When using a distribution, you can manipulate what happens with the original data, e.g. by dropping or repeating data.
Applying a Weight Function
You can weigh any arbitrary imported or numeric data by a Weight Function. A Weight Function is defined by a class that implements the interface com.rapiddweller.model.function.WeightFunction:
public interface WeightFunction extends Weight {
double value(double param);
}
When using a weight function, Benerator will serve data items in random order and as often as implied by the function value. Benerator automatically evaluates the full applicable number range (as defined by numerical min/max or number of objects to choose from) and normalize the weights. There is no need to provide a pre-normalized distribution function. You may define custom Weight Functions by implementing the WeightFunction interface.
Applying a Sequence
A Sequence is basically a number generator. It can provide a custom random algorithm, a custom weighted number generator or a unique number generation algorithm.
For a list of predefined sequences, see Section 8.3, “Sequences”. The definition of a custom sequence is described in Section 9.5, “Custom Sequences”.
Importing Weights
When importing data from data sources, you have additional options for specifying weights. They are different when importing simple data or entities.
Importing primitive data weights
When importing primitive data from a CSV file, each value is expected to be in an extra row. If a row has more than one column, the content of the second column is interpreted as weight. If there is no such column, a weight of 1 is assumed. Benerator automatically normalizes over all data objects, so there is no need to care about manual weight normalization. Remember to use a filename that indicates the weight character, using a suffix like '.wgt.csv' or 'wgt.xls'.
If you, for example, create a CSV file roles.wgt.csv:
customer,7
clerk,2
admin,1
and use it in an configuration like this:
<generate type="user" count="100">
<attribute name="role" source="roles.wgt.csv" />
</generate>
this will create 100 users of which about 70 will have the role 'customer', 20 'clerk' and 10 'admin'.
Weighing imported entities by attribute
when importing entities, an entity attribute can be chosen to represent the weight by specifying distribution=" weighted[attribute-name]". Remember to indicate, that the source file contains entity data by using the correct file suffix, e.g. '.ent.csv' or ' .ent.xls'
Example: If you are importing cities and want to weigh them by their population, you can define a CSV file cities.ent.csv:
name,population
New York,8274527
Los Angeles,3834340
San Francisco,764976
and e.g. create addresses with city names weighted by population, when specifying
<generate type="address" count="100" consumer="ConsoleExporter">
<variable name="city_data" source="cities.ent.csv" distribution="weighted[population]"/>
<id name="id" type="long" />
<attribute name="city" script="city_data.name"/>
</generate>
Nesting Entities
Entities can form composition structures, which are generated most easily by recursive <generate> structures.
Consider a database schema with a db_user and a db_customer table. Each row in the db_customer table is supposed to have a row with the same primary key in the db_user table. So an easy way to implement this is to nest db_customer generation with db_user generation and use the outer db_user's id value for setting the db_customer id:
<generate type="db_user" count="10" consumer="db">
<id name="id" strategy="increment" />
...
<generate type="db_customer" count="1" consumer="db">
<attribute name="id" script="{db_user.id}" />`
...
</generate>
</generate>
Imposing one-field business constraints
Simple constraints, e.g. formats can be assured by defining an appropriate Generator or regular expression, e.g.
<setup>
<import domains="product" />
<!-- create products of random attribs & category -->
<generate type="db_product" count="1000" pageSize="100">
<attribute name="ean_code" generator="EANGenerator"/>
<attribute name="name" pattern="[A-Z][A-Z]{5,12}"/>
<consumer ref="db"/>
</generate>
</setup>
Imposing multi-field-constraints
For supporting multi-field-constraints, you can use a prototype-based approach: Provide a Generator by a variable element. This generator creates prototype objects (or object graphs) which are used as prototype. They may be Entities, JavaBeans or Maps. For example, this may be an importing generator. On each generation run, an instance is generated and made available to the other sub generators. They can use the entity or sub elements by a source path attribute:
<setup>
<import domains="person"/>
<generate type="db_customer" consumer="db">
<variable name="person" generator="PersonGenerator"/>
<attribute name="salutation" script="person.salutation"/>
<attribute name="first_name" script="person.givenName"/>
<attribute name="last_name" script="person.familyName"/>
</generate>
</setup>
The source path may be composed of property names, map keys and entity features, separated by a dot.
Default Attribute Settings
Usually most entities have common attribute names, e.g. for ids or audit data. You can specify default settings by column name:
<defaultComponents>
<id name="ID" type="long" source="db" strategy="sequence" param="hibernate_sequence"/>
<attribute name="VERSION" values="1"/>
<attribute name="CREATED_AT" generator="currentDateGenerator"/>
<attribute name="CREATED_BY" values="rapiddweller"/>
<attribute name="UPDATED_AT" generator="currentDateGenerator"/>
<attribute name="UPDATED_BY" values="rapiddweller"/>
</defaultComponents>
If a table has a column which is not configured in the Benerator descriptor but as defaultComponent, Benerator uses the defaultComponent config. If no defaultComponent config exists, Benerator falls back to a useful standard setting.
Settings
You can define global settings in the descriptor file:
<setting name="my_name" value="Volker" />
or import several of them from a properties file:
<include uri="my.properties" />
Querying Information from a System
Arbitrary information may be queried from a system by a 'selector' attribute, which is system-dependent. For a database SQL is used:
<generate type="db_order" count="30" pageSize="100">
<reference name="customer_id" source="db" selector="select id from db_customer" cyclic="true" />
<consumer ref="db"/>
<!-- automatically chosen by Benerator -->
</generate>
Using cyclic="true", the result set will be re-iterated from the beginning when it has reached the end.
You may apply a distribution as well:
<generate type="db_order_item" count="100" pageSize="100">
<attribute name="number_of_items" min="1" max="27" distribution="cumulated"/>
<reference name="order_id" source="db" selector="select id from db_order" cyclic="true"/>
<reference name="product_id" source="db" selector="select ean_code from db_product" distribution="random"/>
<consumer ref="db"/>
</generate>
The result set of a selector might be quite large, so take care, which distribution to apply:
When using weights, the complete result set is loaded into RAM. Such a distribution should not be applied to result sets of more than 100.000 elements (this applies for most sequences as well). A WeightFunction should be restricted to at most 10.000 elements.
'Unlimited' sequences are
-
'expand'
-
'randomWalk'
-
'repeat'
-
'step'
You can use script expressions in your selectors, e.g.
selector="{ftl:select ean_code from db_product where country='${country}'}"
The script is resolved immediately before the first generation and then reused. If you need dynamic queries, that are re-evaluated, you can specify them with double brackets:
selector="{{ftl:select ean_code from db_product where country='${shop.country}'}}"
Example:
<generate type="shop" count="10">
<attribute name="country" values="DE,AT,CH"/>
<generate type="product" count="100" consumer="db">
<attribute name="ean_code" source="db" selector="{{ftl:select ean_code from db_product where country='${shop.country}'}}"/>
</generate>
</generate>
Attribute Metadata Reference
Descriptive Attribute Metadata
| name | description | default |
|---|---|---|
| name | name of the feature to generate | |
| type | type of the feature to generate | string |
| nullable | tells if the feature may be null | true |
| mode | controls the processing mode: (normal | ignored |
| pattern | uses a regular expression for String creation or date format pattern for parsing Dates. | |
| values | provides a comma-separated list of values to choose from | |
| unique | whether to assure uniqueness, e.g. unique="true". Since this needs to keep every instance in memory, use is restricted to 100.000 elements. For larger numbers you should use Sequence-based algorithms. | false |
| min | the minimum Number or Date to generate | 1 |
| max | the maximum Number or Date to generate | 9 |
| granularity | the resolution of Numbers or Dates to generate | 1 |
| minLength | the minimum length of the Strings that are generated | |
| maxLength | the maximum length of the Strings that are generated |
Constructive Attribute Metadata
| name | description | default |
|---|---|---|
| generator | uses a Generator instance for data creation | |
| nullQuota | the quota of null values to create | 0 |
| converter | the class name of a Converter to apply to the generated objects | |
| dataset | a (nestable) set to create data for, e.g. dataset="US" for the United States | |
| locale | a locale to create data for, e.g. locale="de" | default locale |
| source | A system, EntityIterator or file to import data from. | |
| selector | A system-dependent selector to query for data. | |
| trueQuota | the quota of true values created by a Boolean Generator. | 0.5 |
| distribution | the distribution to use for Number or Date generation. This may be a Sequence name or a WeightFunction class name. | |
| cyclic | auto-resets the generator after it has gone unavailable | false |
Scripts
Scripts are supported in
-
descriptor files
-
properties files
-
DbUnit XML files
-
CSV files
-
Fixed column width files
A script is denoted by curly braces, e.g. {'Hi, I am ' + my_name}. This syntax will use the default script engine for rendering the text as, e.g. 'Hi,
I am Volker'. The default script engine is set writing <setup defaultScript="..."> in the decriptor file's root element. If you want to use
different script engines at the same time, you can differ them by prepending the scripting engine id, e.g. {ftl:Hi, I am ${my_name}} or {ben:'Hi, I
am ' + my_name}. Scripts in Benerator descriptors are evaluated while parsing.
If you need to dynamically calculate data at runtime, use a script attribute, e.g.:
<attribute name="message" script="'Hi, ' + user_name + '!'" />
In the 'script' attribute, curly braces are not necessary.
Using scripts you can access
-
environment variables, e.g. JAVA_HOME
-
JVM parameters, e.g. benerator.validate
-
any JavaBean globally declared in the Benerator setup, e.g. db
-
the last generated entity of each type, e.g. db_user
-
the entity currently being generated and its attributes, e.g. this.id
-
entities generated in outer
<generate>elements -
helper variables in the
<generate>element, e.g. person.familyName -
predefined or custom FreeMarker methods (when using FreeMarker as script language)
-
Static Java methods and attributes, e.g. System.getProperty('user.home')
-
instance methods and attributes on objects in the context, e.g. db.system
Variable names used in scripting may not contain points - a point always implies resolution of a local feature of an object, e.g. person.familyName resolves the familyName attribute/property/key of a person.
this
In a script, the keyword 'this' always refers to the entity currently being generated. You can use this to construct attributes which have dependencies to each other:
<generate type="product">
<id name="id" />
<attribute name="code" script="'ID#' + this.id" />
</generate>
Handling Errors
onError
Several descriptor elements support an onError attribute. It determines an error severity and how Benerator should behave in case of errors.
The default severity is 'fatal', which causes Benerator to stop execution.
Other available severities are ignore, trace, debug, info, warn, error, which mainly influence the log level in which errors are reported, but do not stop execution.
<generate type="product" count="1000" onError="fatal" consumer="db">
<!-- component setup here -->
</generate>
BadDataConsumer
For errors that are raised by a consumer, you have the alternative option to catch them and write the data which has caused the error to an alternative consumer. For example, you can write the problematic data to a CSV file named ' errordata.csv' and postprocess it:
<generate type="product" count="1000" consumer="**new BadDataConsumer(new CSVExporter('errors.csv'),** **db.inserter())">
<!-- component setup here -->
</generate>
Note that this cannot work properly with a database which uses batch processing (see 'Using Databases').